

















智源研究院發布超大規模新型預訓練模型“悟道·文匯”
2021年1月11日,北京智源人工智能研究院發布面向認知的超大規模新型預訓練模型“文匯”,旨在探索解決當前大規模自監督預訓練模型不具有認知能力的問題,這一項目由智源研究院發起的“悟道”攻關團隊完成。
“文匯”模型不僅使用數據驅動的方法來建構預訓練模型,還將用戶行為、常識知識以及認知聯系起來,主動“學習”與創造。本次發布的“文匯”模型與1月初OpenAI剛剛發布的DALL·E和CLIP這兩個連接文本與圖像的大規模預訓練模型類似,“文匯”模型能夠學習不同模態(文本和視覺領域為主)之間的概念,可以實現“用圖生文”等任務,具有一定的認知能力。“文匯”模型參數規模達113億,僅次於DALL·E模型的120億參數量,是目前我國規模最大的預訓練模型,並已實現與國際領先預訓練技術的並跑。
智源研究院學術副院長、清華大學計算機系唐杰教授認為,GPT-3等超大型預訓練模型在處理復雜的認知推理任務上,例如開放對話、基於知識的問答、可控文本生成等,結果仍然與人類智能有較大差距。智源研究院院長、北京大學信息技術學院黃鐵軍教授指出,“文匯”模型針對性地設計了多任務預訓練的方法,可以同時學習文→文、圖→文以及圖文→文等多項任務,實現對多個不同模態的概念理解。經過預訓練的“文匯”模型不需要進行微調就可以完成“用圖生文”等任務,對模型進行微調則可以靈活地接入如視覺問答、視覺推理等任務。
“文匯”模型應用即將上線
目前,“文匯”已支持基於認知推理的多種自然語言及跨模態應用任務,部分應用即將與搜狗、阿裡巴巴、學堂在線、智譜.AI、循環智能等機構合作上線。目前已有四個樣例應用可用於展示模型效果。
(一)基於上傳圖片的開放域問答
本應用基於圖片文本的多模態認知預訓練百億模型,可以支持用戶上傳圖片后,針對圖片內容進行提問或生成圖片的一句話描述。如上傳圖片后詢問“圖片中的電腦在水杯的什麼位置?”或“生成對應商品圖片的一句話描述”。將於未來大規模應用於阿裡的電商場景。

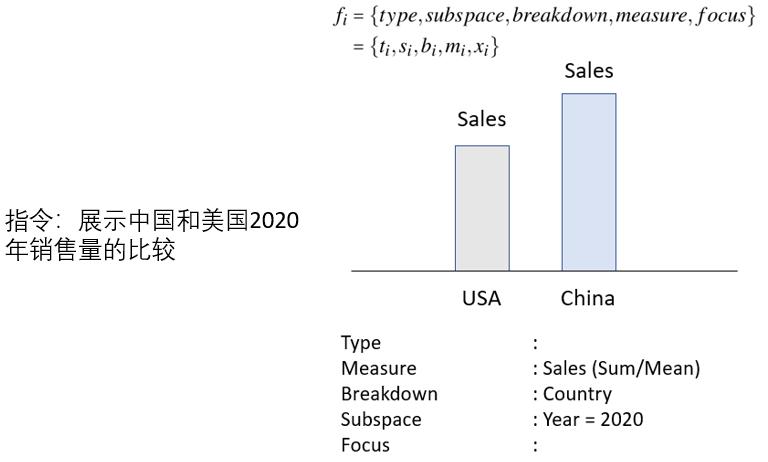
(二)Talk to Data,用語言操作數據可視化
本應用基於數據可視化技術,通過將自然語言轉化為可視化查詢語句,從而達到“上傳圖表,輸入指令,輸出可視化圖像”的功能目標。隻需要一句自然語言的話,就可以實現數據的可視化自動統計與查詢。
(三)基於預訓練語言模型的詩詞創作應用
本應用可以基於輸入的詩歌題目、朝代、作者,生成仿古詩詞。與傳統基於規則或監督學習的詩歌生成不同,這個應用創作的詩歌來自於自然語言的生成,且無標注數據進行fine-tune,並且可以模仿任意詩人創作任意新穎題目的詩歌。
下面是基於模型自動作詩的結果:
贈抗疫英雄
君王歌裡贈英雄,百萬雄師劈毒煙。
況是人民勤努力,更加眾志與國捐。
團結團結再團結,萬眾一心戰瘟神。
沔水橋邊香霧起,暗送瘟神過漢陽。
(四)可控人設的開放域問答
本應用支持用戶上傳問題,並生成具有人物角色風格的定制化文本回答。與傳統的開放式問答不同,“文匯”模型生成的答案具有人設的語言特色,問答內容趣味橫生。目前該應用將計劃在搜狗的問答場景中使用。
“悟道”項目下一步研發計劃
目前,“悟道”項目研究團隊正在視覺等更廣泛的范圍內,對大規模自監督預訓練方法開展探索研究,已經啟動了四類大規模預訓練模型研制,包括“文源”(以中文為核心的超大規模預訓練語言模型)、“文匯”(面向認知的超大規模新型預訓練模型)、“文瀾”(超大規模多模態預訓練模型)和“文溯”(超大規模蛋白質序列預訓練模型)。2020年11月14日,智源研究院已發布了“文源”(以中文為核心的超大規模預訓練語言模型)第一階段26億參數規模的中文語言模型。下一步,智源研究院將聯合優勢單位加快四類大規模預訓練模型的研發進度。特別是“文匯”模型,未來將著力在多語言、多模態條件下,提升完成開放對話、基於知識的問答、可控文本生成等復雜認知推理任務的能力,使其更加接近人類水平。計劃在今年6月實現“中文自然語言應用系統”“基於圖文增強和知識融入的圖文應用系統”“基於認知的復雜認知系統”等一批各具特色的超大規模預訓練模型,以期達到對國際領先AI技術的趕超,盡快實現我國在國際AI前沿技術研究的領跑。
分享讓更多人看到 
相關新聞
人民日報社概況 | 關於人民網 | 報社招聘 | 招聘英才 | 廣告服務 | 合作加盟 | 供稿服務 | 數據服務 | 網站聲明 | 網站律師 | 信息保護 | 聯系我們
服務郵箱:kf@people.cn 違法和不良信息舉報電話:010-65363263 舉報郵箱:jubao@people.cn
互聯網新聞信息服務許可証10120170001 | 增值電信業務經營許可証B1-20060139
廣播電視節目制作經營許可証(廣媒)字第172號 | 互聯網藥品信息服務資格証書(京)-非經營性-2016-0098
信息網絡傳播視聽節目許可証0104065 | 網絡文化經營許可証 京網文[2020]5494-1075號 | 網絡出版服務許可証(京)字121號 | 京ICP証000006號 | 京公網安備11000002000008號
人 民 網 版 權 所 有 ,未 經 書 面 授 權 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
評論

-
關注
微信微博快手
 第一時間為您推送權威資訊
第一時間為您推送權威資訊
 報道全球 傳播中國
報道全球 傳播中國
 關注人民網,傳播正能量
關注人民網,傳播正能量
